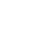实现功能:
1.点击开始说话按钮,调用录音功能
2.在说话过程中通过websocket实时发送语音数据,并将数据处理成二进制流传输
3.在说话过程中展示相应音浪效果
4.点击关闭按钮,停止说话,并获取识别的文字内容
效果展示:
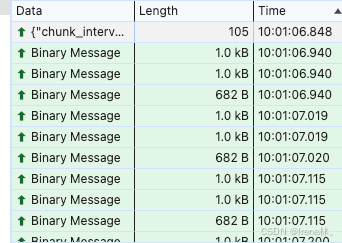
1.websocket传输数据格式
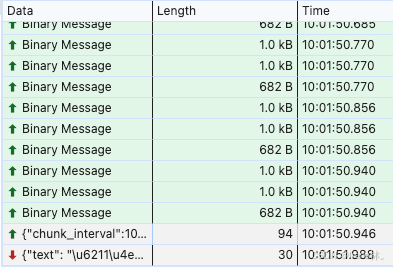
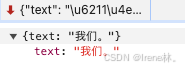
2.语音识别的文字内容
3.音浪效果展示

整体效果如下:

完整代码如下:
语音识别的文字为:{ { resText || "--" }}
清华大学新闻中心版权所有,清华大学新闻网编辑部维护,电子信箱: news@tsinghua.edu.cn
Copyright 2001-2020 news.tsinghua.edu.cn. All rights reserved.